
重庆中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2022-11-10 来源:黑马程序员 浏览量:

1.为什么要进行sql优化
因为没有进行sql优化的语句执行性能低下。而性能低下的原因:sql语句欠佳,索引失效,服务器参数设置不合理(缓冲、线程数)
本文整个优化过程 主要是围绕索引进行
2.Mysql安装启动配置(CentOS7)
1)版本介绍与选择
目前主流版本 5.x
5.0-5.1: 相当于4.x版本的延续,升级维护
5.4 -5.x: Mysql整合了三方公司的新存储引擎 (推荐使用5.7版本,当前比较稳定的版本)
2)mysql安装-rpm
2.1检查服务器msyql安装情况,有就先卸载自带的mysql【Centos7 默认安装mariadb】
> rpm -qa|grep 软件名字 【检查命令】
>
> rpm -e --nodeps 软件包名 【卸载命令】
>
> yum remove 软件包名 【卸载命令】
rpm -qa|grep mariadb
//卸载方式一
rpm -e --nodeps mariadb-libs-5.5.44-2.el7.centos.x86_64
//卸载方式二(建议使用yum卸载,可自动处理依赖关系)
yum remove mariadb-libs-5.5.44-2.el7.centos.x86_64
2.2下载安装包
https://downloads.mysql.com/archives/community/
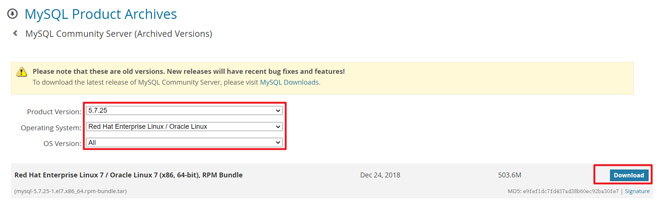
2.3解压安装包到/usr/local/mysql
mkdir /usr/local/mysql tar -xvf mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar -C /usr/local/mysql
2.4按照顺序安装rpm安装包
#先安装依赖 yum install net-tools #注意: 下列安装包的安装顺序不能变 rpm -ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-5.7.25-1.el7.x86_64.rpm rpm -ivh mysql-community-devel-5.7.25-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm rpm -ivh mysql-community-client-5.7.25-1.el7.x86_64.rpm rpm -ivh mysql-community-server-5.7.25-1.el7.x86_64.rpm
2.5验证是否安装成功【查看mysql版本】
mysqladmin --version
2.6mysql常用命令
systemctl status mysqld 查看mysql服务状态
systemctl start mysqld 启动mysql服务
systemctl stop mysqld 停止mysql服务
systemctl enable mysqld 设置开机时启动mysql服务,避免每次开机启动mysql
2.7设置密码
/usr/bin/mysqladmin -u root password 'new-password'
2.8登录
mysql -u root -p
2.9设置root用户远程连接权限和密码
mysql> grant all privileges on *.* to 'root' @'%' identified by 'remote-password'; mysql> flush privileges;
2.10开放端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent firewall-cmd --reload
3.逻辑分层,存储引擎,解析过程
1)逻辑分层
连接层 - 提供与客户端连接的服务
服务层 - 1.提供各种用户使用的接口(增删改查,等) 2.提供sql优化器(mysql query optimizer)
引擎层 - 提供了各种存储数据的方式(InnoDB,MyISAM)
存储层 - 存储数据
2)存储引擎
2.1常用引擎(InnoDB, MyISAM)
MyISAM:ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键,如果执行大量的select,insert MyISAM比较适合
InnoDB:支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB,特别是针对多个并发和QPS较高的情况
2.2区别
1.MyISAM不支持事务,而InnoDB支持。InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交。
2. MyISAM只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持行级锁和事务,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在有索引时是有效的,无索引或索引失效都会锁全表的。
3. InnoDB支持外键,MyISAM不支持。
4. InnoDB的主键范围更大,最大是MyISAM的2倍。
5. InnoDB不支持全文索引,而MyISAM支持。全文索引是指对char、varchar和text中的每个词(停用词除外)建立倒排序索引。MyISAM的全文索引其实没啥用,因为它不支持中文分词,必须由使用者分词后加入空格再写到数据表里,而且少于4个汉字的词会和停用词一样被忽略掉。
6. MyISAM支持GIS数据,InnoDB不支持。即MyISAM支持以下空间数据对象:Point,Line,Polygon,Surface等。
7. 没有where的count(*)使用MyISAM要比InnoDB快得多。因为MyISAM内置了一个计数器,count(*)时它直接从计数器中读,而InnoDB必须扫描全表。所以在InnoDB上执行count(*)时一般要伴随where,且where中要包含主键以外的索引列。为什么这里特别强调“主键以外”?因为InnoDB中primary index是和raw data存放在一起的,而secondary index则是单独存放,然后有个指针指向primary key。所以只是count(*)的话使用secondary index扫描更快,而primary key则主要在扫描索引同时要返回raw data时的作用较大。
2.3存储结构
InnoDB 和 Myisam 都是用 B+Tree 来存储数据的。
一般情况3层B+Tree可以存放上百万条数据
3)解析过程
3.1sql编写过程:
select dinstinct.. from.. join.. on.. where.. group by.. having.. order by.. limit..
3.2sql解析过程:
from.. on.. join.. where.. group by.. having.. select dinstinct.. order by.. limit..
4.索引
1)什么是索引
索引: 相当于书的目录,是帮助mysql高效获取数据的数据结构
2)索引类型
普通索引: index 命名: idx_字段名
唯一索引: unique 命名: uk_字段名
主键索引: primary key 命名: pk_字段名
复合索引: 多个字段组成的索引(name,age) 命名: 按索引顺序字段名命名 idx_name_age
复合索引并不一定所有索引字段都会用到。当name已经查询出结果是,不会再去查询age索引
但为了性能考虑建议在sql语句中用到所有的索引字段
3)创建索引
方式一: create 索引类型 索引名 on 表(字段); 方式二: alter table 表名 add constraint 索引名 索引类型(字段);
//简单索引 mysql> create index idx_dept on tb(dept); //唯一索引 mysql> create unique index uk_name on tb(name); //复合索引 mysql> create index idx_dept_name on tb(dept,name); //主键索引 mysql> alter table tb add constraint pk_id primary key(id);
4)删除索引
> drop index 索引名 on 表名;
mysql> drop index uk_name on tb; mysql> drop index idx_dept on tb; mysql> drop index idx_dept_name on tb;
5)查询索引
> show index from 表名;
mysql> show index from tb;
6)不适合创建索引的字段
索引本身需要的存储空间很大的字段
频繁需要修改的字段
很少使用的列 (sql语句中用不到的列)
重复值多的列
5.执行计划
1)数据准备
mysql> create table tab_school_timetable(stid int(3),stname varchar(20),tid int(3)); mysql> create table tab_teacher(tid int(3),tname varchar(20)); mysql> create table tab_teacher_card(tcid int(3), tid int(3),tcdesc varchar(200));
mysql> create table tab_school_timetable(stid int(3),stname varchar(20),tid int(3)); mysql> create table tab_teacher(tid int(3),tname varchar(20)); mysql> create table tab_teacher_card(tcid int(3), tid int(3),tcdesc varchar(200));
2)语法
> explain sql语句;

3)explain信息详解 id
> id:sql语句执行的编号
>
> id值相同,从上往下顺序执行。这个顺序受表数据量的大小影响,先查数据量小的,后查数据量大的
>
> id值不同:先执行id值大的
#查询课程编号为2 或 教师证编号为3 的老师信息 explain select t.tname from tab_teacher t, tab_school_timetable st, tab_teacher_card tc where t.tid = st.tid and t.tid = tc.tcid and (st.stid = 2 or tc.tcid = 3);

#查询教授sql课程老师的描述信息 explain select tc.tcdesc from tab_teacher_card tc where tc.tid = (select st.tid from tab_school_timetable st where st.stname = 'sql' )

4)explain信息详解 select_type
select_type 查询类型
PRIMARY: 主查询,sql中包含有子查询
SUBQUERY: 子查询
SIMPLE: 普通查询 (不含有子查询和union 连接查询的查询)
DERIVED: 衍生查询 (使用到了临时表)
union: 使用到了union 连接查询
union result: 显示拿些表之间使用了union
5)explain信息详解 table
表名
6)explain信息详解 type
> type 索引类型
>
> 常用到的类型system > const > eq_ref > ref > range > index > all
>
> system 性能最高,all性能最低。 实际项目中达到 ref > range 性能就行
>
> system : 表只有中一条数据的主查询
>
> const : 查询结果只有一条数据的sql ,并且索引类型必须为主键索引或者唯一索引
>
> eq_ref : 查询结果可以有多条数据,但满足where判断条件的每一条数据必须是唯一的一条数据(不能多条也不能为0条)。
explain select t.tname from teacher t,teacherCard tc where t.tid = tc.tid; ``` ref : 索引查询返回匹配所有行(0条,多条)
explain select t.tname from tab_teacher t where t.tname = 'ta'; range : 检索指定范围的行,where后面是一个范围查询(between , in , > , < 等 其中in可能会导致索引失效而变成 all)
explain select tc.tcdesc from tab_teacher_card tc where tc.tid between 1 and 2; ``` index : 查询全部索引的数据
explain select t.tid from tab_teacher t; ``` all :查询全部表的数据(sql 将表的所有数据都查了一遍) ,没有用到索引时常出现
explain select st.stname from tab_school_timetable st;
7)explain信息详解 possible_keys
可供选择的索引
8)explain信息详解key
实际用到的索引
9)explain信息详解key_len
实际使用到索引的长度(utf8 1个字符3个字节)
10)explain信息详解ref
表之间的引用-指明当前表所参照的字段
const: 判断条件中用到了常量 或者 显示用到了其他表的那些字段
11)explain信息详解rows
估计查询了表中的数据行数(MySQL认为必须检查以执行查询的行数)
12)explain信息详解extra
> 准备工作
create table t ( a1 char(3), a2 char(3), a3 char(3), index idx_a1(a1), index idx_a2(a2), index idx_a3(a3) );
> using filesort : 性能损耗大,需要额外的查询(排序) ,常见于 order by 语句中
#当排序和查找不是同一个字段就会出现using filesort explain select t.a1,t.a2,t.a3 from t where t.a1 = '' order by a2; //反例 explain select t.a1,t.a2,t.a3 from t where t.a1 = '' order by a1; //正例 #复合索引不能跨列(最佳左前缀)否则会出现using filesort create index idx_a1_a2_a3 on t(a1,a2,a3); explain select t.a1,t.a2,t.a3 from t where t.a1 = '' order by a3; //反例(跨了 a2) explain select t.a1,t.a2,t.a3 from t where t.a2 = '' order by a3; //反例(跨了 a1) explain select t.a1,t.a2,t.a3 from t where t.a1 = '' order by a2; //正例
> using temporary:性能损耗大,用到了临时表,一般出现与 group by 语句中
explain select t.a1,t.a2,t.a3 from t where a1 in ('1','2','3') group by a2; //反例
explain select t.a1,t.a2,t.a3 from t where a1 in ('1','2','3') group by a1; //正例
> using index: 性能提升,只从索引中查询数据,不需要回表查询
>
> using where: 进行了回表查询
drop index idx_a1_a2_a3 on t; create index idx_a1_a2 on t(a1,a2); explain select a1,a2 from t where a1='' and a2 = ''; //正例 explain select a1,a3 from t where a1=''; //反例


> impossible where : where 查询条件永远为fasle
explain select a1 from t where a1='a' and a1 = 'b';

> Using join buffer : MySQL引擎使用了连接缓存,表示sql语句太烂,性能低下
6.慢查询
1)慢查询有什么用
开启慢查询后,可以根据日志信息分析那些SQL语句性能低下,从而针对性的进行优化
2)检查是否开启了慢查询
mysql> show variables like '%slow_query_log%';
3)开启慢查询
#临时开启 - mysql重启后失效 mysql> set global slow_query_log = 1;
#永久开启 - 修改my.cnf 文件 vim /etc/my.cnf
[mysqld] slow_query_log = 1 slow_query_log_file = /var/lib/mysql/localhost-slow.log
4)慢查询阈值
#查看 mysql> show variables like '%long_query_time%'; #临时设置(单位秒) - 重新登陆起效 mysql> set global long_query_time = 2;
#永久设置 - 修改my.cnf 文件 vim /etc/my.cnf
[mysqld] long_query_time = 2
5)查看超过慢查询阈值的sql次数
mysql> show global status like '%slow_queries%';
6)查看超过慢查询阈值具体的sql信息
> 1.查看slow_query_log_file日志文件
>
> 2.使用mysqldumpslow工具
mysqldumpslow --help -s : 排序方式 (r 逆序) -l :锁定时间 -t :查询多少条 -g : 正则表达式 //获取返回记录最多的3个SQL mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow.log //获取访问次数最多的3个SQL mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow.log //按照时间排序,查询前10条包含left join查询语句的sql mysqldumpslow -s t -t 10 -g 'left join' /var/lib/mysql/localhost-slow.log
7.优化总结
```ABAP
优化一般不能一次就优化到最佳效果,需要在开发过程中根据使用情况多次逐步优化
```
> 1. 复合索引保证最佳左前缀原则
>
> 2. 小表驱动大表
>
> 3. 索引建立在经常查询的字段上
>
> 4. 复合索引,尽量使用全索引匹配(说明:假设使用了三个字段建立了一个复合索引,在sql查询中尽量让三个索引都用到)
>
> 5. 不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
>
> 6. 复合索引不能使用不等于( != , <> )和 is null, is not null ,否则索引失效
>
> 7. like 尽量以 ‘常量’ 开头,不要使用 ‘%x%’ ,否则索引失效
>
> 8. 尽量不要使用or ,否则索引失效
>
> 9. 如果必须使用到索引失效的情况,尽量使用索引覆盖(using index),可能会使索引生效,达到性能优化
>
> 10. 将含有in的范围查询放到where条件的最后面,防止索引失效(尽量不使用in)
>
> 11. 连接查询 a.t = b.t 的情况下,将表数据量小的放在左边,表数据量大的放在右边会提高性能
>
> 12. 连接查询 a.t = b.t 的情况下,将 a 表 t 字段加索引会提高性能
>
> 13. 对于左外连接给左表加索引,右外连接给右表加索引
>
> 14. exist 和 in,如果主查询的数据集大,则使用in,如果子查询的数据集大,使用exist
>
> 15. 提高 order by 查询的策略
>
> a、选择使用单路、双路;调整buffer的容量大小
> b、避免使用 select * ...
> c、保证排序字段的 排序一致性




















.jpg)