
重庆中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-11-03 来源:黑马程序员 浏览量:
我们在网页上搜索内容时,常常会看到搜索框跳出与你输入的文字内容相关的搜索项,这个功能是怎么实现的呢?
需求说明:
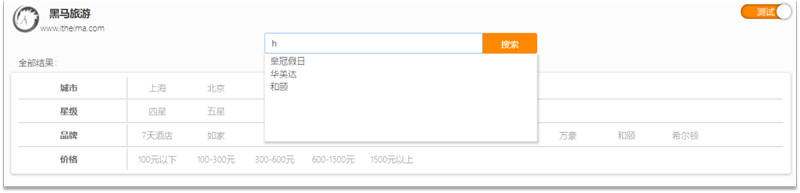
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
使用拼音分词
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:https://github.com/medcl/elasticsearch-analysis-pinyin
安装方式与IK分词器一样,分三步:
①解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试

自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符。
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart。
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等。
假设四级考试通过的心情,通过自定义分词器处理,大概是下面的展现形式:

我们可以在创建索引库时,通过settings来配置自定义的analyzer(分词器),创建代码如下:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "pinyin"
}
}
}
}
}PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
创建倒排索引时:
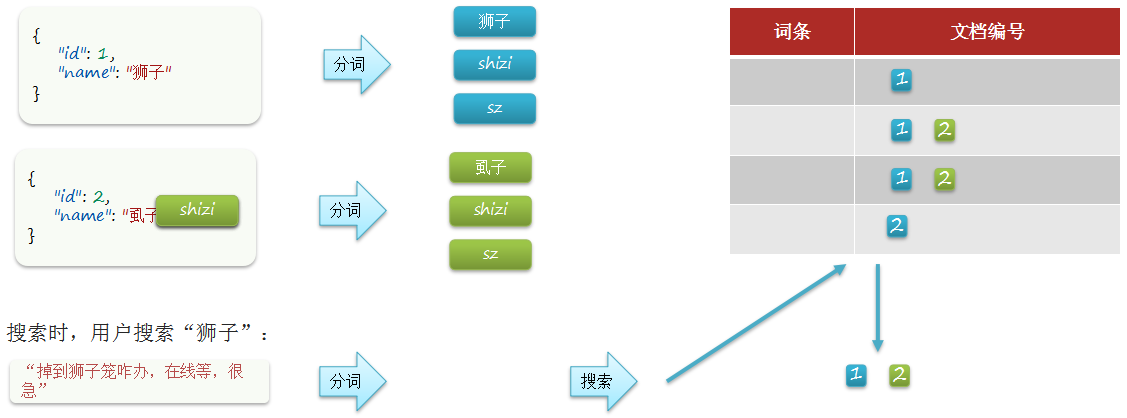
因此字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器;
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word", "filter": "py"
}
},
"filter": {
"py": { ... }
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
completion suggester查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。completion suggester查询
// 创建索引库
PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}// 示例数据
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
completion suggester查询
查询语法如下:
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}注意:自动补全对字段的要求类型是completion类型,字段值是多词条的数组。
案例:实现hotel索引库的自动补全、拼音搜索功能
实现思路如下:
1.修改hotel索引库结构,设置自定义拼音分词器
2.修改索引库的name、all字段,使用自定义分词器
3.索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
4.给HotelDoc类添加suggestion字段,内容包含brand、business
5.重新导入数据到hotel库
注意:name、all是可分词的,自动补全的brand、business是不可分词的,要使用不同的分词器组合
RestAPI实现自动补全
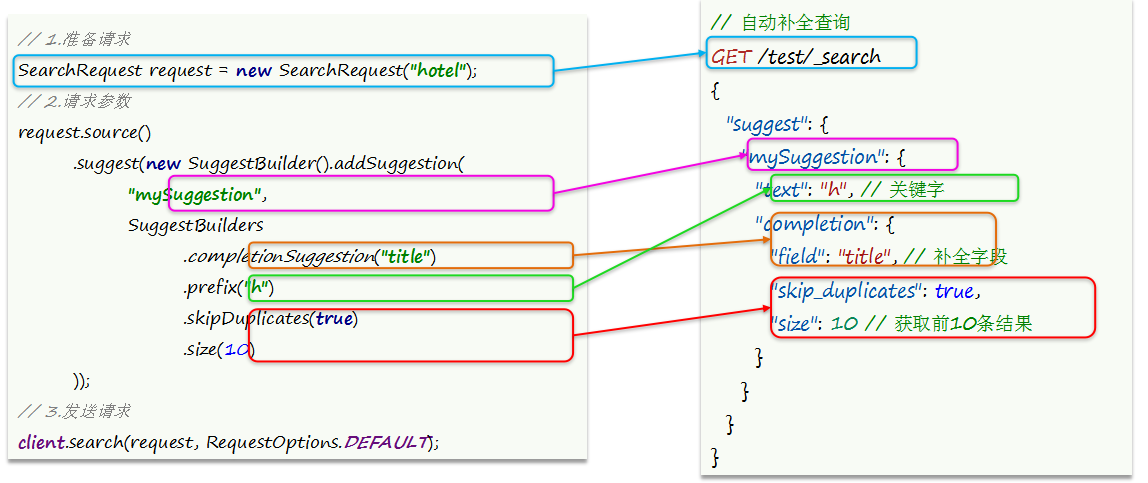
先看请求参数构造的API:
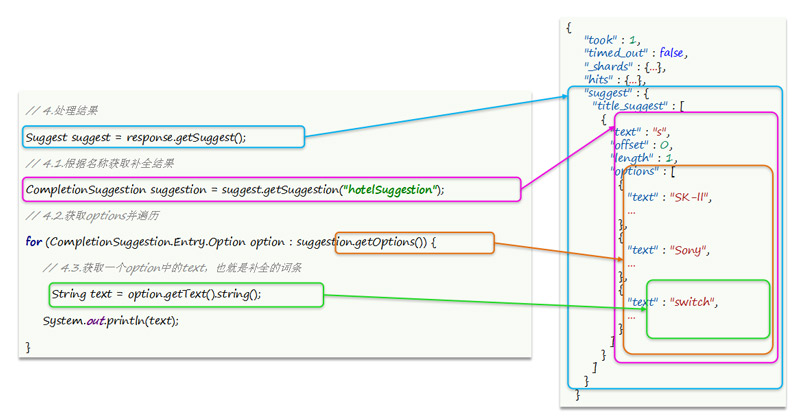
再来看解析:
案例2:实现酒店搜索页面输入框的自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求:
在服务端编写接口,接收该请求,返回补全结果的集合,类型为List
猜你喜欢:




















.jpg)